CS184 Summer 2025 Final Project Final Report
Ambient Global Illumination with Caching

Link to webpage: 98sean.github.io/cs184-final-project/final/index.html
Link to GitHub repository
Link to presentation video
Link to presentation slides
Link to Demo
Abstract
Radiance, authored by Greg Ward, is a gold standard in physically-based rendering, renowned for its ability to simulate realistic lighting in architectural and interior scenes. One of its key innovations is ambient global illumination (GI), an efficient technique for caching and interpolating indirect diffuse light. We implemented Ward's ambient caching algorithm in the CS184 pathtracer, developing an adaptive octree-based system that replaces expensive Monte Carlo sampling with spatial interpolation. Our implementation achieves 15 - 30× speedups for interior scenes while maintaining visual quality. Through evaluation on Cornell Box scenes with varying geometric complexity, we demonstrate that ambient caching remains a powerful optimization for modern path tracers, particularly for architectural visualization where indirect lighting exhibits high spatial coherence.
Technical approach
Summary
We implemented an octree-based ambient global illumination caching system inspired by Greg Ward's Radiance renderer. Our approach accelerates indirect lighting computation by caching and interpolating previously computed values, achieving 15 - 30× speedup over Monte Carlo path tracing in HW3.
We initially prototyped with a uniform grid to validate the caching concept, then developed the adaptive octree structure to handle
non-uniform sample distributions more efficiently. The system integrates seamlessly with the existing pathtracer through the
-g flag for ambient GI and -V for cache visualization.
Our implementation consists of the following four core components:
- Adaptive Octree Data Structure: A hierarchical spatial subdivision that dynamically adapts to scene complexity. The octree automatically subdivides when leaf nodes exceed 8 samples, concentrating resolution where illumination varies most while maintaining memory efficiency in uniform regions.
- Efficient Octree Traversal for Cache Queries: \( O(log(n)) \) cache lookups through octree traversal with spatial pruning. Search regions are defined as cubic volumes \( (12 × \text{min_spacing}) \) around query points, with the octree efficiently discarding non-intersecting branches during traversal.
- Cache Miss/Hit Handling: When queries find no nearby samples (cache miss), the system computes indirect illumination using Monte Carlo integration and stores the result in the octree. Cache hits enable fast weighted interpolation from nearby samples, eliminating expensive ray casting. The formula \( w = (1 / \text{distance}) × \text{normal_similarity} \) ensures smooth transitions while prioritizing geometrically similar samples.
- Cache Visualization: We developed a visualization system that renders cache points as colored spheres, with color indicating ambient intensity (blue = low, green = medium, red = high). This helps us understand cache distribution and debug grid spacing parameters.
Adaptive Octree Data Structure
Fig 2.1 shows octree subdivision adaptive to the scene. As new cache samples in red are added in regions with complex illumination, the octree automatically subdivides when any leaf exceeds 8 samples, maintaining efficient spatial organization throughout the rendering process.
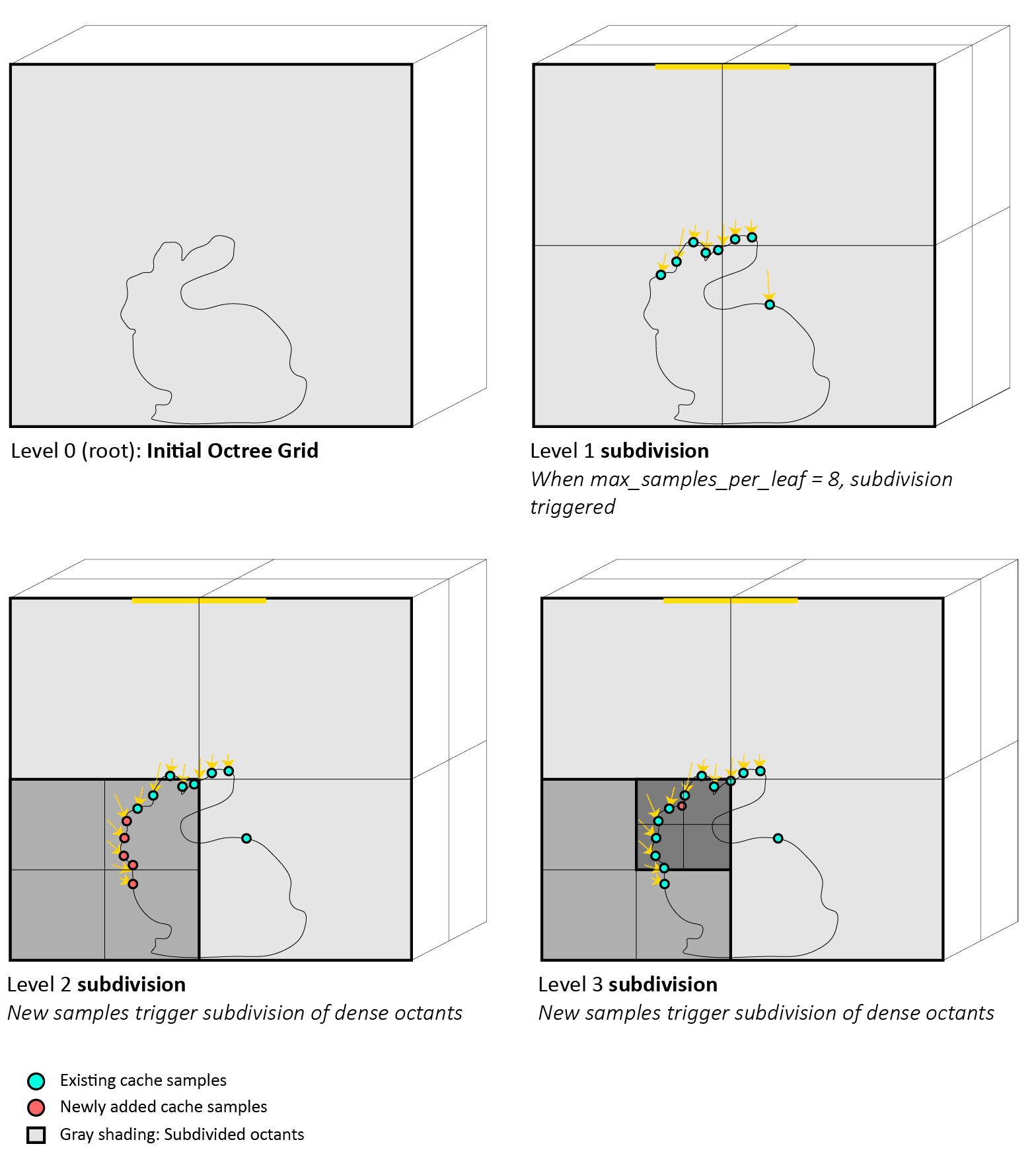
Figure 2.1 illustrates the progressive octree refinement during ambient cache construction for the Cornell Box bunny scene.
Starting from an empty octree (Level 0), the first 8 cache samples are computed when rays hit the bunny's surface under
the area light, triggering the initial subdivision into 8 octants (Level 1). As rendering continues, new cache samples
(shown in red) are generated when cache queries miss, particularly in the bottom-left octant where the bunny's body receives complex
indirect illumination from the surrounding walls. When this octant accumulates 8 samples, it automatically subdivides
(Level 2), creating finer spatial resolution precisely where illumination are strongest. This process continues
adaptively (Level 3), with the octree depth increasing only in regions with high sample density, such as areas with
geometric detail or varying illumination. Empty octants and uniform regions remain at coarser levels, optimizing both memory usage and
query performance. This adaptive refinement ensures \( O(log(n)) \) lookup complexity while concentrating computational resources where
they contribute most to rendering quality.
Efficient Octree Traversal for Cache Queries
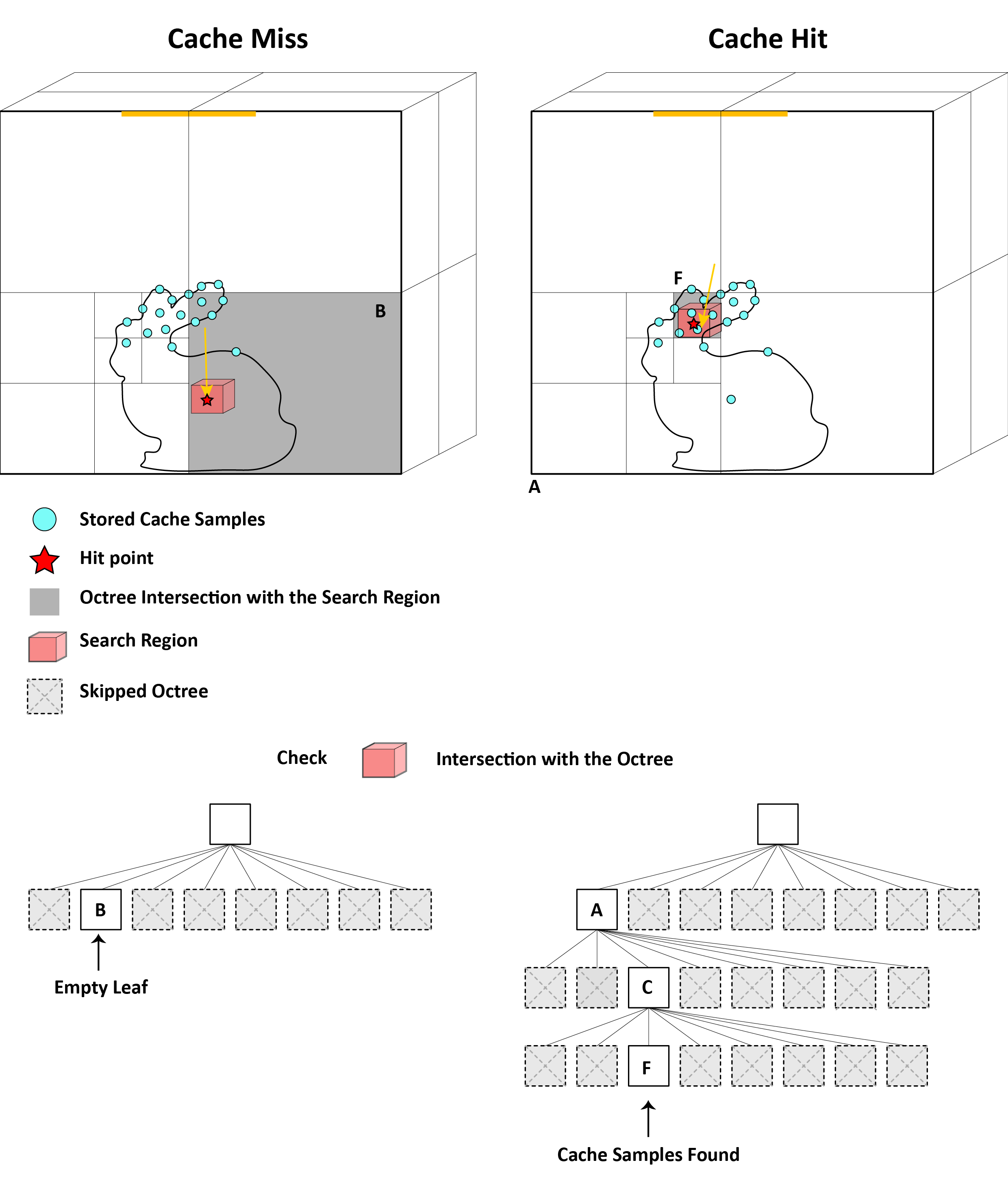
Figure 2.2 demonstrates the spatial acceleration provided by our octree data structure for ambient cache queries. When a ray intersects a surface and requires indirect illumination, we define a cubic search region around the hit point with dimensions \( 12 × \text{min_spacing} \) \( (± 6 × \text{min_spacing} \) in each direction \( ) \). The octree traversal algorithm efficiently prunes the search space by testing bounding box intersections at each level. In the left panel, the search region intersects only the bottom-right octant, allowing the algorithm to immediately discard seven of the eight root-level children without examination. The traversal continues recursively, visiting only octants whose bounding boxes intersect the search region, until reaching leaf nodes that either contain cache samples or are empty. The right panel illustrates a deeper tree structure where cache samples have accumulated over multiple rendering passes, requiring traversal through multiple subdivision levels to locate relevant entries. This spatial pruning achieves \( O(log(n)) \) query complexity compared to the \( O(n) \) complexity of exhaustive search, where \( n \) is the total number of cached samples.
Ambient Cache Miss vs Hit: Computation vs Interpolation
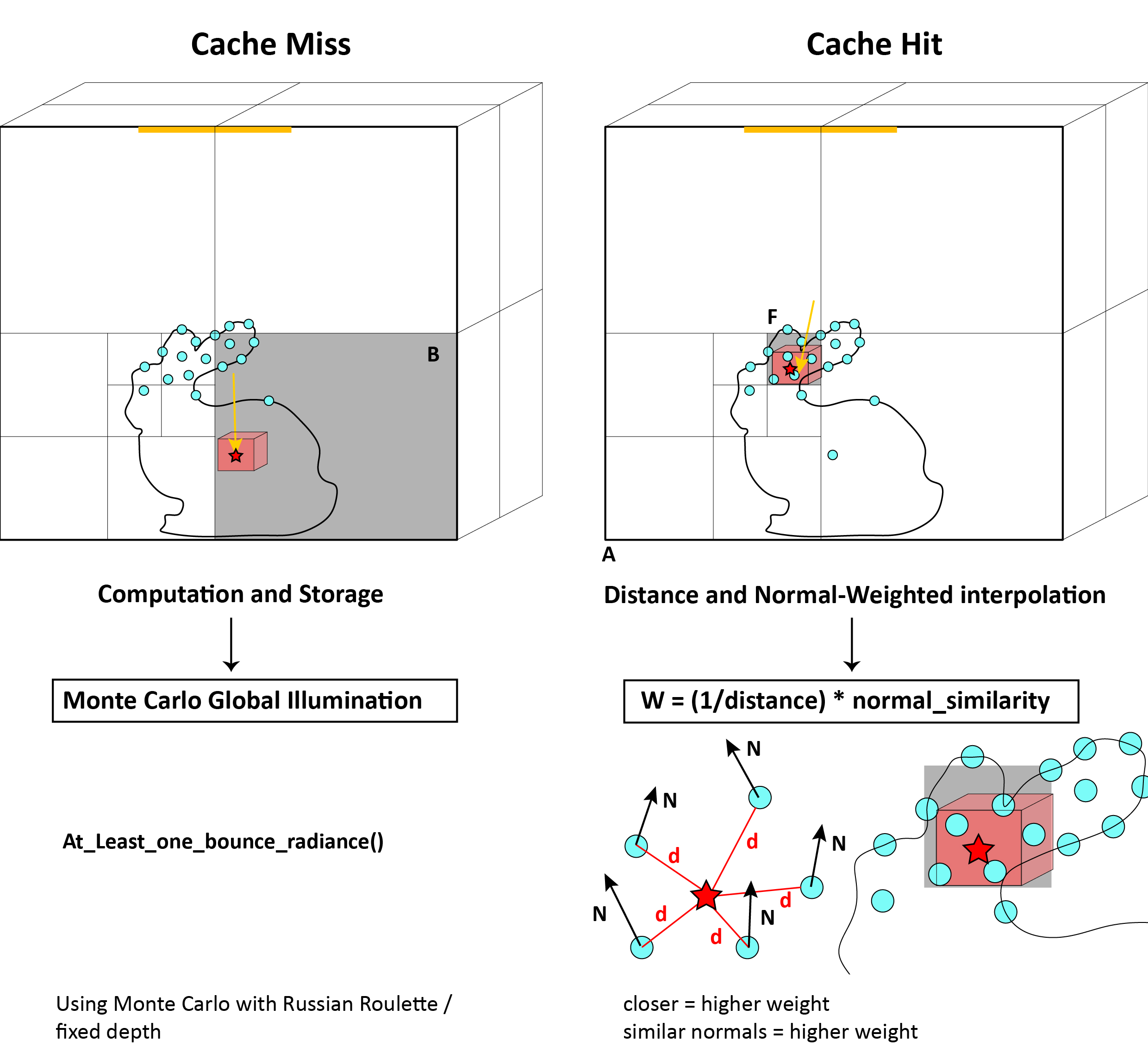
Figure 2.3 illustrates the fundamental performance distinction between cache misses and cache hits in our ambient GI implementation. When the octree traversal fails to locate nearby cache samples (left), a cache miss occurs, triggering the expensive computation of indirect illumination using Monte Carlo integration. The computed ambient value is then stored in the octree for future reuse. In contrast, when the octree contains nearby samples within the search region (right), a cache hit enables fast interpolation without additional ray casting.
Our interpolation algorithm weights cached samples based on inverse distance and normal similarity:
- \[ w = (1 / \text{distance}) × \text{normal_similarity} \]
The weighted interpolation combines nearby cache samples using:
- \[ C = \frac{\sum_{i} w_i C_i}{\sum_{i} w_i}, \quad \text{where} \quad w_i = \frac{1}{d_i} \cdot \cos(\theta_i) \]
Here \( d_i \) is the distance to sample \( i \) and \( \theta_i \) is the angle between surface normals.
This approach ensures that closer samples and those with similar surface orientations contribute more heavily to the final result. This weighted average ensures smooth transitions between cached values while prioritizing samples that are both spatially close and geometrically similar to the query point.
Problems encountered
We encoutered the following two issue in this project:
-
Cache Density Parameter Tuning: Finding the optimal
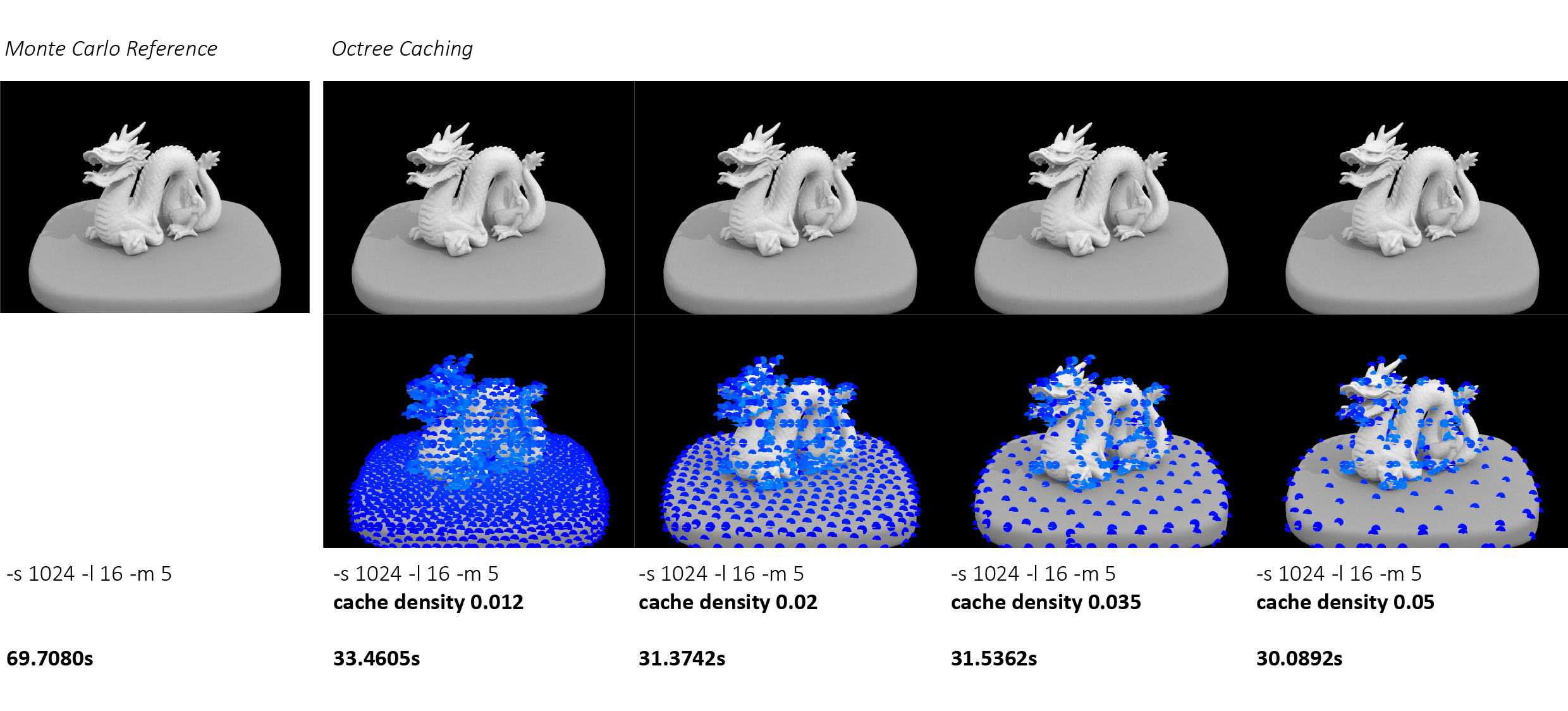
min_spacingparameter for different scenes proved more complex than anticipated. Too sparse spacing (> 0.05) caused visible interpolation artifacts and banding, while too dense spacing (< 0.01) negated performance benefits and increased memory usage. We addressed this through extensive experimentation and developed our cache visualization system with-Vflag to visually debug cache distribution. This allowed us to identify that interior scenes work best with densities around 0.012 - 0.02, providing a good balance between quality and performance. -
Debugging Cache Interpolation Artifacts: Early implementations showed unexpected color bleeding and discontinuities
at cache boundaries. These artifacts were particularly visible in the Cornell Box's colored walls. Through our visualization system,
we discovered that our initial interpolation wasn't properly accounting for surface normal orientation, which means that samples
from differently oriented surfaces were being incorrectly blended. Adding normal similarity weighting
dot(n1, n2)to our interpolation formula resolved these artifacts and produced smoother results.
Lessons learned
Through implementing ambient caching, we gained deep appreciation for how spatial coherence in indirect illumination can be exploited for massive performance gains. Interior scenes, where light bounces predictably off nearby surfaces, are ideal candidates for caching strategies. We learned that even without sophisticated gradient extrapolation, simple distance-weighted interpolation can produce visually acceptable results when samples are distributed appropriately. This insight reinforces that understanding the physical properties of light transport can guide algorithmic optimizations.
Our initial grid-based cache served as a valuable prototype but quickly revealed its limitations. The octree implementation taught us that adaptive spatial data structures are essential when dealing with non-uniform phenomena like illumination. The ability to concentrate samples where they matter most, which is near geometric details and illumination discontinuities, while maintaining sparse sampling in uniform regions, provided both memory efficiency and quality improvements. This lesson extends beyond rendering to any domain with non-uniform spatial data.
We initially aimed to implement Ward's complete algorithm with rotation gradients and translational gradients. However, the recursion issues forced us to simplify. Rather than viewing this as failure, we learned that a working, simpler solution often provides most of the benefit of a theoretically superior but complex approach. Our gradient-free implementation still achieved 10 - 30× speedups with good visual quality, validating the pragmatic choice to prioritize functionality over theoretical completeness.
Results
Demo
The demo shows how to render a CBbunny.dae scene with ambient GI -g and cache visualization -V enabled. The command line parameters -g and -V are currently not available in the interactive mode.
-
To show the bunny rendering with octree caching, the CLI is:
-t 8 -s 1024 -l 16 -m 5 -r 480 360 -g -f a_demo_nocache ../dae/sky/CBbunny.dae -
To show the cache visualization , the CLI is:
-t 8 -s 1024 -l 16 -m 5 -r 480 360 -V -g -f a_demo_cache ../dae/sky/CBbunny.dae
- For the results above, we used 14 threads for the renderings but it always caused app crashes when recording on Zoom. For demonstration, we just temporarily used 8 threads instead.
- The cache densities can only be modified in the code. There is no command line parameter supporting it.
- If the demo video is disabled in PDF, please click on the link: https://youtu.be/5qZoQvpq2xk
Octree Cache Performance
Our octree-based ambient caching system demonstrates significant performance improvements over Monte Carlo path tracing while maintaining visual quality. We evaluated the system using Cornell Box scenes with varying geometric complexity and cache densities.
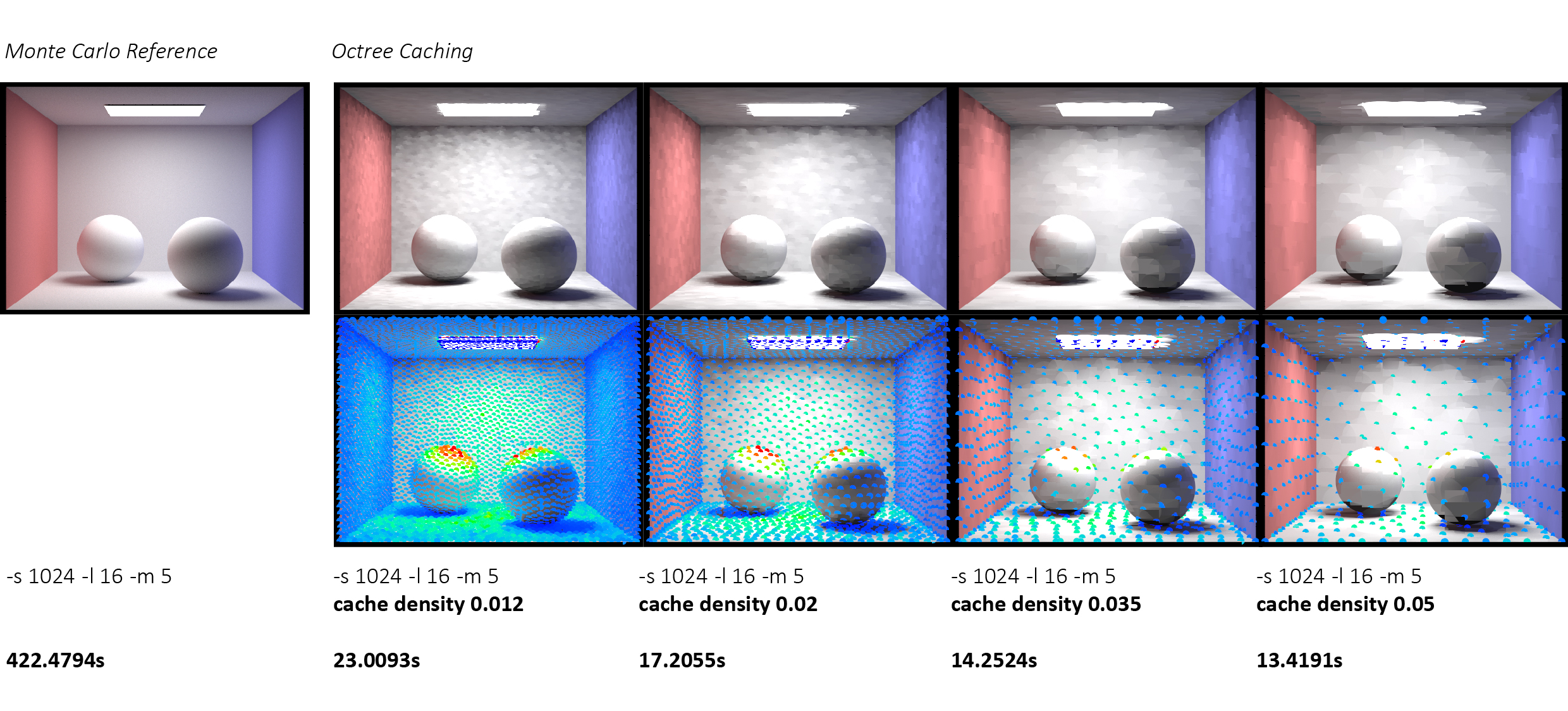
| Method | Cache Density | Render Time | Speedup |
|---|---|---|---|
| Monte Carlo | - | 422.48s | 1.0× |
| Octree Cache | 0.012 | 23.01s | 18.3× |
| Octree Cache | 0.02 | 17.21s | 24.5× |
| Octree Cache | 0.035 | 14.25s | 29.6× |
| Octree Cache | 0.05 | 13.42s | 31.5× |
The spheres scene showcases dramatic speedups, achieving up to 31.5× faster rendering with the sparsest cache.

The bunny scene, with its intricate geometry, presents a more challenging test:
| Method | Cache Density | Render Time | Speedup |
|---|---|---|---|
| Monte Carlo | - | 491.54s | 1.0× |
| Octree Cache | 0.012 | 32.21s | 15.3× |
| Octree Cache | 0.02 | 22.99 | 21.4× |
| Octree Cache | 0.035 | 18.76s | 26.2× |
| Octree Cache | 0.05 | 17.73s | 27.7× |
The complex bunny geometry requires denser sampling than the simple spheres, as evidenced by the cache visualization showing concentrated samples around the model's detailed features. Despite the complexity, we still achieve 15 - 27× speedups depending on quality requirements.
Our results reveal a clear density-performance trade-off where sparser caches render faster but introduce interpolation artifacts, with the optimal density depending on scene complexity and quality requirements. The cache visualizations confirm that our octree successfully implements adaptive sampling, concentrating samples near geometric details and illumination discontinuities while maintaining sparse sampling in uniform regions like the Cornell Box walls. Across both simple and complex scenes, we observe consistent speedups of 15 - 30× for interior scenes, demonstrating the robustness of our approach. Most importantly, at a density of 0.012, our cached results are nearly indistinguishable from the Monte Carlo reference while still providing order-of-magnitude performance improvements, validating that ambient caching can deliver both quality and speed for architectural visualization applications.
Impact of Sample Count on Quality
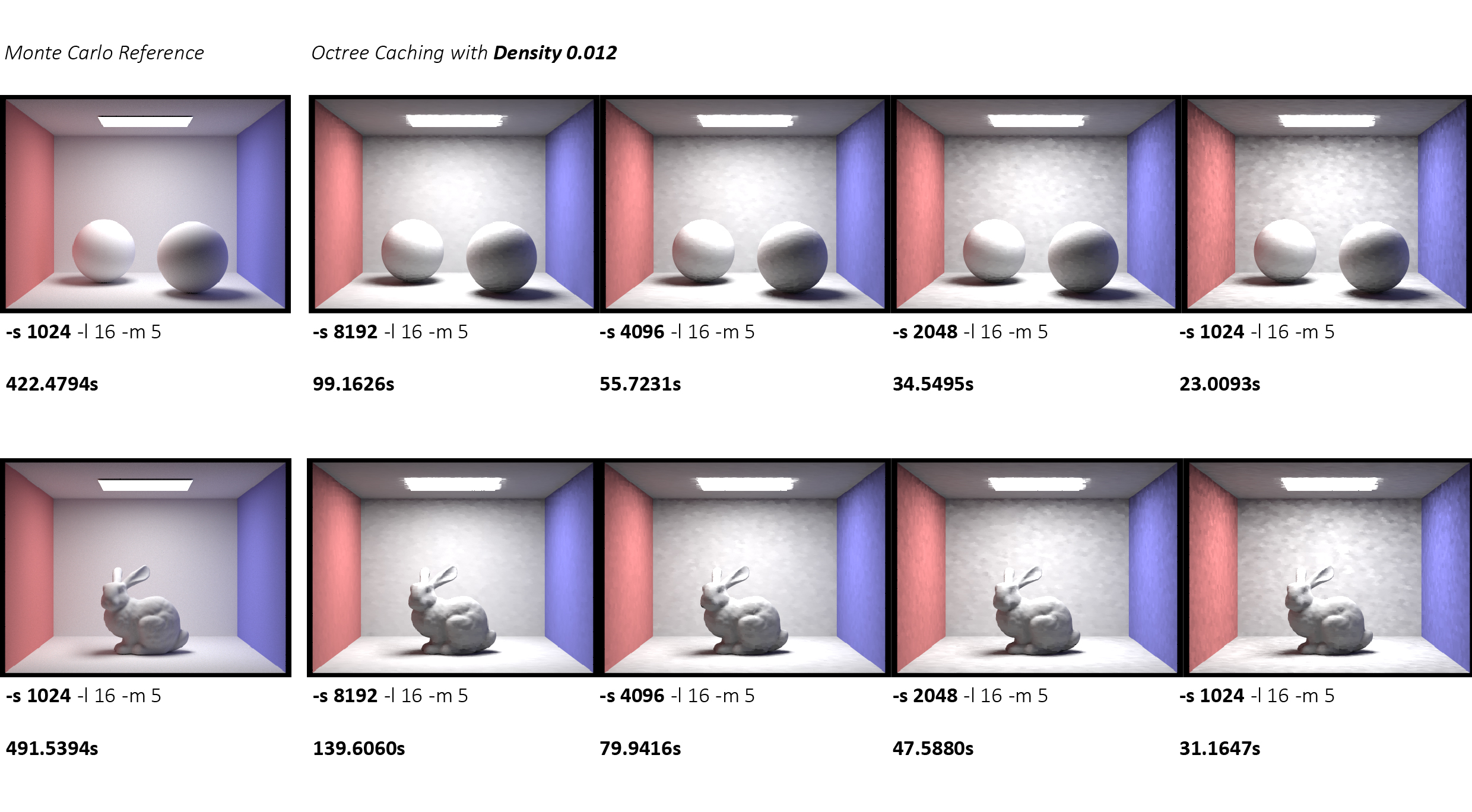
For CBspheres.dae, the results are the following:
| Samples/Pixel | Render Time | Speedup vs MC |
|---|---|---|
| Monte Carlo (1024) | 422.48s | 1.0× |
| 8192 | 99.16s | 4.3× |
| 4096 | 55.72s | 7.6× |
| 2048 | 34.55s | 12.2× |
| 1024 | 23.01s | 18.3× |
For CBbunny.dae, the results are the following:
| Samples/Pixel | Render Time | Speedup vs MC |
|---|---|---|
| Monte Carlo (1024) | 491.54s | 1.0× |
| 8192 | 139.61s | 3.5× |
| 4096 | 79.94s | 6.1× |
| 2048 | 47.59s | 10.3× |
| 1024 | 31.16s | 15.8× |
While our default configuration uses 1024 samples per pixel, we investigated how sample count affects rendering quality with cached ambient GI.
Increasing sample count significantly improves visual quality by reducing variance in the cached values. With 8192 samples, discontinuous patches and interpolation artifacts virtually disappear, producing results nearly indistinguishable from the Monte Carlo reference. However, this comes at the cost of reduced speedup, from 18× at 1024 samples to 4× at 8192 samples. For production rendering where quality is paramount, using 4096 samples provides an excellent balance with 6 - 7× speedup and minimal visible artifacts. This demonstrates that our caching system's quality can be tuned based on application requirements: fast preview renders at 1024 samples or high-quality finals at 4096 - 8192 samples.
Comparison with Initial Grid-based Prototype
Before implementing the octree structure, we prototyped with a uniform 3D grid cache to validate the ambient caching concept:

| Grid Spacing | Render Time | Speedup |
|---|---|---|
| Monte Carlo | 80.69s | 1.0× |
| 0.5 | 9.78s | 8.3× |
| 1.0 | 6.71s | 12.0× |
| 1.5 | 4.72s | 17.1× |
| 2.0 | 5.26s | 15.3× |
The grid-based approach revealed fundamental limitations that motivated our octree implementation. The uniform grid wastes memory by allocating cells even in empty space, consuming resources for areas with no geometry. More critically, the fixed resolution cannot adjust to local complexity. Fine grids with 0.5 spacing show severe interpolation artifacts from over-sampling, while coarse grids at 1.5 - 2.0 spacing produce unusable results with visible banding. Unlike our octree which achieves 15 - 30× speedups with excellent quality, the grid approach offers no quality-performance sweet spot where both metrics are acceptable. The cache visualization (bottom row) clearly shows the grid's inability to adapt, with samples uniformly distributed regardless of geometric or illumination complexity. While this prototype validated the ambient caching concept, it demonstrated that adaptive spatial structures are essential for production-quality ambient GI, ultimately leading us to develop the octree-based solution.
Limitations
Unlike the Cornell Box scenes which achieved 15 - 30× speedups, this exterior scene shows only marginal improvement (- 2×). The cache visualization reveals the followin reasons: samples are distributed across the entire model surface but capture primarily direct illumination, which doesn't benefit from caching. Without surrounding walls to create complex indirect bounces, the ambient cache cannot exploit spatial coherence in indirect lighting. There simply isn't much indirect lighting to cache.
This result validates that ambient caching is specifically optimized for interior architectural scenes where indirect illumination from wall-to-wall light bounces dominates the lighting complexity. For exterior scenes or objects in open environments, the overhead of cache management provides little benefit over direct Monte Carlo sampling. This aligns with Ward's original Radiance design, which targeted architectural interior visualization where indirect lighting calculations are most expensive and spatially coherent.
Future Work
Our implementation successfully demonstrates ambient GI caching with significant speedups, but has several limitations that present opportunities for future work. Most notably, we were unable to implement Ward's full gradient-based extrapolation due to recursive computation issues, instead relying on distance and normal-weighted interpolation. While our results show this simplified approach still provides good quality, implementing proper gradients through techniques like finite differences or deferred computation could further improve interpolation accuracy.
The system currently requires manual tuning of cache density parameters for different scenes, as we observed optimal values ranging from 0.012 for complex geometry to 0.05 for simple scenes. Future work could implement automatic density selection based on scene analysis or adaptive refinement during rendering. Additionally, our current implementation focuses on diffuse interreflection and does not handle glossy or specular indirect illumination, which would require extending the cache to store directional information.
References
Primary reference:
Supporting reference:
Contributions
Xin Zhou:
- Literature review of grid-based cache and octree based cache algorithm
- Implementation of grid/octree cache system
- Final Renderings and diagram drawings
- Report write-up, slides and demo
Sean Lee:
- Literature review of grid-based cache and octree based cache algorithm
- Command Line Parameter implementation
- Scene rendering testing and debugging for grid and octree data structure
- Report write-up and slides
Archisha Nangia:
- Literature review of grid-based cache and octree based cache algorithm
- Cache memory management
- Scene rendering testing and debugging for grid and octree data structure
- Slides and videos
Carlynda Gao:
- Literature review of grid-based cache and octree based cache algorithm
- Interpolation techniques and implementation
- Scene rendering testing and debugging for grid and octree data structure
- Slides and videos